Image matching based OCR system using OpenCV


We are working with printed text and a limited character set in this project, but it is easy extensible to include all unicode characters. While modern OCR systems based on neural networks produce the greatest results, it's useful to be familiar with traditional computer vision pipelines that accomplish the same function without further training. We disassemble the system into three components: Enrollment, Recognition, and Detection
from collections import defaultdict
import glob
import os
import heapq
import cv2
import numpy as np
import matplotlib.pyplot as plt
test_image = cv2.imread('test_img.jpg', cv2.IMREAD_GRAYSCALE)
all_character_imgs = glob.glob('alphabets' + "/*")
# SIFT feature extractor
sift = cv2.SIFT_create()
characters = []
for each_character in all_character_imgs:
character_name = "{}".format(os.path.split(each_character)[-1].split('.')[0])
characters.append([character_name, cv2.imread(each_character, cv2.IMREAD_GRAYSCALE)])
def threshold_otsu(image, *args, **kwargs):
total_pixels = image.shape[0] * image.shape[1]
mean_weight = 1.0 / total_pixels
his, bins = np.histogram(image, np.arange(0, 257))
final_thresh = -1
final_value = -1
intensity_arr = np.arange(256)
for thresh in bins[1:-1]:
left = np.sum(his[:thresh])
right = np.sum(his[thresh:])
w_left = left * mean_weight
w_right = right * mean_weight
mub = np.sum(intensity_arr[:thresh] * his[:thresh]) / float(left)
muf = np.sum(intensity_arr[thresh:] * his[thresh:]) / float(right)
value = w_left * w_right * (mub - muf) ** 2
if value > final_value:
final_thresh = thresh
final_value = value
output = image.copy()
output[image > final_thresh] = 255
output[image < final_thresh] = 0
return output
def convolve_2d(image, kernel):
kernel = np.flipud(np.fliplr(kernel))
output = np.zeros_like(image)
h, w = image.shape
padded = np.zeros((h + 2, w + 2))
padded[1:-1, 1:-1] = image
for i in range(w):
for j in range(h):
output[j, i] = (kernel * padded[j: j + 3, i: i + 3]).sum()
return output
def resize(image, factor=2):
img_h, img_w = image.shape
h, w = img_h * factor, img_w * factor
output = []
for i in range(img_h):
for j in range(img_w):
for _ in range(factor):
output.append(image[i][j])
for _ in range(factor - 1):
output += output[-img_w * factor:]
output = np.asarray(output).reshape(h, w)
return output
def gaussian_kernel(size, sigma):
kernel_1d = np.linspace(- (size // 2), size // 2, size)
gauss = np.exp(-0.5 * np.square(kernel_1d) / np.square(sigma))
kernel_2d = np.outer(gauss, gauss)
return kernel_2d / np.sum(kernel_2d)
def norm(a, b, n):
if not isinstance(a, np.ndarray):
a = np.asarray(a)
if not isinstance(b, np.ndarray):
b = np.asarray(b)
res = np.sum(np.abs(a - b) ** n, axis=-1) ** (1. / n)
return res
def norm_l4(a, b):
return norm(a, b, 4)
def get_component(components, idx, img, show=False):
component = components[idx]
left, right = component['left'], component['right']
top, bottom = component['top'], component['bottom']
image = img[left:right+1, top:bottom+1]
if show:
_ = plt.imshow(image, cmap='gray')
return (left, top, right-left+1, bottom-top+1), image
One way to match characters in a text document is to extract them and compare them to the reference set, returning the one with the highest correlation. However, this approach has certain drawbacks, since we must change the reference set picture resolution to match the target resolution. This challenge can be solved by producing many scales of reference characters and conducting an exhaustive search, although this can be computationally expensive. In this project, we adopt a different technique; rather than directly matching photos, we extract features and compare their descriptors. During enrolment, we will perform SIFT feature extraction.
There are many feature descriptors which can be useful like Harris Corners, Histogram of Oriented gradients and SIFT. We will explore SIFT in the post.
Scale-Invariant Feature Transform (SIFT) is a technique for detecting local features, unlike many other feature descriptors SIFT is rotation and scale invariant which means that descriptors of an image and its equivalent image which is slightly rotated and scaled are similar.
The Laplacian (derivative) of an image reveals regions of fast intensity change; to eliminate noise, the image is first smoothed. This filter is also known as the laplacian of gaussian, and while calculating the derivative at each point is computationally expensive, we can approximate this function by taking the difference of gaussian filtered images with varying σ. After finding DoG (Difference of gaussian) we iterate through the filtered image and find local extrema over scale and space where each pixel is compared with neighbouring pixels and pixels from top and bottom scales. We apply the same procedure on different resolutions to obtain SIFT keypoints.
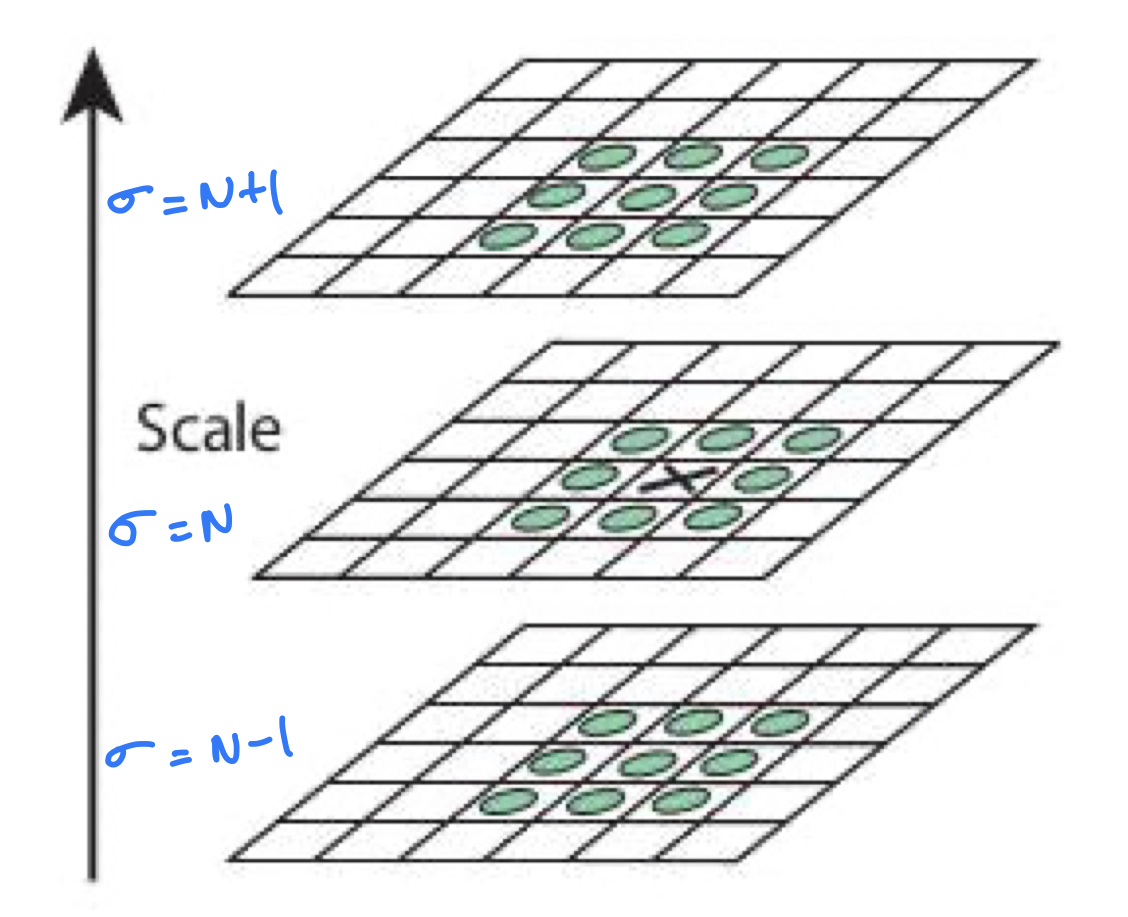
Keypoints obtained in the above step under goes through some filtering to find more accurate interest points. A neighbourhood is taken around the keypoint location depending on the scale, and the gradient magnitude and direction is calculated in that region. An orientation histogram with 36 bins covering 360 degrees is created and the highest peak in the histogram is taken and any peak above 80% of it is also considered to calculate the orientation.
Ones the orientation is adjusted, A 16x16 neighbourhood around the keypoint is taken and it is divided into 16 sub-blocks of 4x4 size. For each sub-block, 8 bin orientation histogram is created. So a total of 128 bin values are available. This is the feature descriptor which is rotation and scale invariant
def enroll(characters, n_padding=3):
char_features = {}
for name, img in characters:
# we pad the image to make sure we have background separating the
# character pixel else SIFT wont be able find the keypoints
img = np.pad(img, n_padding, constant_values=255.)
# optionally scale the image
if min(img.shape) < 18:
# resize the image to 2X resolution
img = resize(img, 2)
keypoint, descriptor = sift.detectAndCompute(img, None)
char_features[name] = descriptor.tolist() if descriptor is not None else []
return char_features
reference_char_features = enroll(characters)
Detection is the technique of extracting characters from a test image; this is sometimes referred to as connected component analysis. While there are several strategies available, I chose to clip the components using a Depth First Search strategy. Prior to using DFS, we binarize the image to ensure that it contains only background and foreground pixels and that our algorithm investigates and saves the foreground pixels. Let us attempt to locate components for the following test image.
_ = plt.imshow(test_image, cmap='gray')

h, w = test_image.shape
binary_image = threshold_otsu(test_image).astype(np.int16)
component_features = {}
# set background pixel values to -1 to facilitate DFS
for i in range(h):
for j in range(w):
if binary_image[i][j] == 255:
binary_image[i][j] = -1
As we are using recursive algorithm, we have to make sure we increase the recursion stack limit
sys.setrecursionlimit(10**6)
def get_neighbours(k):
neighbours = [
[1, 0],
[0, 1],
[-1, 0],
[0, -1],
]
if k == 8:
diag_neighbours = [
[-1, -1],
[1, 1],
[-1, 1],
[1, -1]
]
neighbours += diag_neighbours
return neighbours
def connected_components(arr, n_component, components, h, foreground, n_dir=8):
arr = arr.copy()
height, width = len(arr), len(arr[0])
visited = set()
# get neighbourhood pixel indices
neighbour_idx = get_neighbours(n_dir)
def dfs(i, j, n_component, visited):
if i < 0 or i >= height or j < 0 or j >= width or arr[i][j] == -1 or (i, j) in visited:
# return if the current index is either out of bounds or already visited
return
visited.add((i, j))
arr[i][j] = n_component
# capture character border coordinates in a hash map while exploring
components[n_component]['left'] = min(components[n_component].get('left', float('inf')), i+h)
components[n_component]['right'] = max(components[n_component].get('right', float('-inf')), i+h)
components[n_component]['top'] = min(components[n_component].get('top', float('inf')), j)
components[n_component]['bottom'] = max(components[n_component].get('bottom', float('-inf')), j)
for x, y in neighbour_idx:
dfs(i + x, j + y, n_component, visited)
# iterate from top to bottom and left to right
for j in range(width):
for i in range(height):
if arr[i][j] == foreground and (i, j) not in visited:
dfs(i, j, n_component, visited)
n_component += 1
return n_component
heights = []
k = 0
components = defaultdict(dict)
flag = True
p = 0
h, w = binary_image.shape
bimg = binary_image.copy().astype(np.int16)
# split image into rows
for i in range(h):
temp = (bimg[i, :] == 0.).any()
if temp == flag:
if flag:
heights.append([i, i])
else:
heights[-1][1] = i
flag = not flag
for i in range(h):
for j in range(w):
if bimg[i][j] == 255:
bimg[i][j] = -1
# process each row from top to bottom and left
# to right to maintain english reading order
for h1, h2 in heights:
p = connected_components(
bimg[h1:h2+1, :],
p,
components,
h1,
foreground=0,
)
component_features = {}
# OTSU thresholding worked better than simple global thresholding
bin_image = threshold_otsu(test_image).astype(np.int16)
for n_component in components:
component = components[n_component]
left, right = component['left'], component['right']
top, bottom = component['top'], component['bottom']
img = bin_image[left:right + 2, top:bottom + 2]
# smoothen image with gaussian kernel to remove noise
g_kernel = gaussian_kernel(size=3, sigma=1)
img = convolve_2d(img, g_kernel)
# pad the image so that we will have some background pixels
# so that SIFT and identify features
img = np.pad(img, 3, constant_values=255.).astype(np.uint8)
# scale to image to 2X size if its small
# SIFT was not able to identify features if the image size is low
if min(img.shape) < 18:
img = resize(img, 2)
keypoint, descriptor = sift.detectAndCompute(img, None)
component_features[n_component] = {
'coordinates': {
'x': top,
'y': left,
'w': bottom - top + 1,
'h': right - left + 1,
},
'descriptor': descriptor.tolist() if descriptor is not None else [],
}
Following the extraction of SIFT features, the final step is to match the descriptors and associate the characters with their corresponding alphabet based on their similarity score. We will filter ambiguous matches using an extended version of Lowe's ratio. It works by calculating the ratio between the top two matches, and if it is less than a threshold, we consider the minimum distance between feature vectors, but additionally, if the condition fails, we consider the average distance between all the descriptors. I discovered this method through experimentation, and I've had good results.
def matcher(test, reference, measure, thresh=0.8, reverse=False):
arr = []
for s_idx, test_feature_vec in enumerate(test):
heap = []
for t_idx, ref_char_feature_vec in enumerate(reference):
# distance measure to get the distance between
# two feature vectors (Histogram of oriented gradients)
distance = measure(test_feature_vec, ref_char_feature_vec)
heapq.heappush(heap, distance)
if len(heap) >= 2:
min_1 = heapq.heappop(heap)
min_2 = heapq.heappop(heap)
# checking for lowe's ratio
if (min_1 / min_2) < thresh:
arr.append(round(min_1, 2))
else:
# my improvement
if heap:
arr.append(round(sum(heap)/len(heap), 2))
return arr
min_thresh = float('-inf')
# threshold is found by trail and error : any distance which is
# less than this threshold is considered as unknown character
max_thresh = 194
# l4 norm seemed to perform better than l2 norm
dist_measure = norm_l4
detected_ch = {}
for n_component in component_features:
test_desc = component_features[n_component]['descriptor']
score = float('inf')
match_ch = 'UNKNOWN'
for ch in reference_char_features:
reference_desc = reference_char_features[ch]
scores = matcher(test_desc, reference_desc, dist_measure)
mean_score = sum(scores) / len(scores) if scores else float('inf')
# get the alphabet with minimum score which in the threshold range
if min_thresh <= mean_score <= max_thresh:
if mean_score < score:
score = mean_score
match_ch = ch
detected_ch[n_component] = match_ch
We can observe some of the recognized characters after SIFT feature matching. I was able to achieve F1 score ~ 0.97 with this approach.
_ = get_component(components, 4, test_image, show=True)

detected_ch[4]
_ = get_component(components, 11, test_image, show=True)

detected_ch[11]